1. はじめに
1.1 ご挨拶
本記事は、MATLAB /Simulink Advent Calendar 2023の12日目です。
東工大 ロケットサークルCREATEが2022年11月に打ち上げました、小型ロケットC-59Jのロール制御系 について紹介します。
MATLAB を用いて設計したロール制御系について、主に次の3つの観点から記述しました。
制御対象のモデル化とパラメータ推定
制御ゲインの決定
安定性評価
本記事中で取り上げたMATLAB コードは、Github にも上げていますのでご覧ください。
github.com
ロケットの機体構造については、ぜひこちらの記事をご覧ください。
tgkhtknk.hatenablog.com
1.2 背景
全国にはいくつもの学生ロケットサークルがあり、東京都大島町 、秋田県 能代市 、和歌山県 和歌山市 などにて、共同打上実験を年に数回実施しています。
規模としましては、全長1~2m程度のロケットを、高度数百~数千mへ打ち上げています。
これまで、ロール制御 (機軸方向まわりの回転角制御) に挑戦したサークルは複数ありますが、制御系の設計法と制御結果について詳しく紹介した例は見当たりません。
ロケットの製作には半年~1年程度を要し、本番は1発勝負であるため、制御ゲインの試行錯誤的な調整ができない難しい環境にあります。
そこで本記事では、成功裡に終えたC-59Jのロール制御系に焦点を当てその詳細を紹介することで、今後ロール制御に挑戦する方々にとって有益な情報になればと思います。
さらに、MATLAB /Simunik界隈の皆様に向け、MATLAB を使用して達成した成果を共有したいと思います。
2. ロール制御用ハードウェアの構成
図1に、小型ロケットC-59Jのうち、ロール制御に関連するハードウェアの模式図を示します。
ロールモーメントは、2枚の動翼 が発生させる揚力により得ます。
2枚の動翼は、傘歯車を介して1個のMAXON社製エンコーダ付きギアモータにより駆動します。エンコーダには512pulse/countの2相インクリメンタルエンコーダを用い、ギアボックスのギア比は29.16です。
この構成により、四逓倍を用いることで出力軸の角度は約0.006度の分解能で計測されます。
MCU にはESP32を用います。
ピトー管により計測した対気速度、MEMS 9軸センサにより計測した機体系角速度、エンコーダにより計測した動翼角度などから、適切なモータ電圧指令値を生成し、モータドライバへPWM信号を送信します。
同時に、各センサ値の計測および計測値と制御値の保存を行います。
さらに、機体内から外の景色および動翼の動きを撮影し、ロール制御の成否を定性的に確認するために、2台の小型カメラを搭載します。
図1 ハードウェア構成
3. 制御対象および制御系のモデル化
3.1 概要
図2に制御対象および制御系を簡易に表したブロック線図を示します。
ただし、目標ロール角は、固定値が与えられるものと仮定します。
与えられた目標ロール角と、姿勢推定器が推定したロール角推定値、およびピトー管を用いて求めた対気速度推定値をもとに、目標動翼角度決定器が目標動翼角度を決定します。
次に、目標動翼角度と、エンコーダを用いて計測した動翼角度計測値から、動翼角度制御器がモータに電圧を印加します。
モータ・ギアボックス・傘歯車・動翼から構成されるモータ-動翼系は、印加された電圧に応じて回転します。
このとき、動翼角度および対気速度に応じて発生するロールモーメントが、機体のロール角を変化させます。
図2 全体ブロック線図
3.2 動翼角度制御のモデル化
3.2.1 モータ・動翼系のモデル化とシステム同定
図2において、ロール角のフィードバックループ 内に、動翼角度のフィードバックループ が存在します。まずは、この部分をモデル化してみましょう。
DCモータにおいて、電圧 (s)までの伝達関数 は、式(1)のように二次系で表せることが知られています。今回は、モータ-動翼系のモデル化にこの式を用いることとします。
ここで、
はモータ-動翼系の
機械的 ・電気的特性から決まる固定値です。
は、こちらの記事を参考にした
システム同定 実験により求めました。
図3 モータ-動翼系システム同定 実験における入出力の時間変化
下記のMATLAB コードを用いて、システム同定 をしました。MATLAB を使えば簡単だなあ...(中身を知らなすぎると危ないけど)
システム同定 実験で得られた、1列目がduty比、2列目が角度計測値、3列目が前サンプリングとの時刻差であるcsv ファイルを読み込んでいます。
図4に、同定実験における角速度の測定値 (図3の下段と同じ) 、およびシステム同定 結果を用いたシミュレーション結果の角速度の時間変化を示します。(上記コードで得られるfigure(1)です。)
赤色の線は、システム同定 実験における入力電圧(図3の上段)を、システム同定 結果に基づくモデルに入力したときの応答をシミュレーションしたものです。
いい感じに同定できてそうですね。
図4 システム同定 実験および同定結果を用いたシミュレーションの角速度
3.2.2 動翼角度制御器のモデル化
今回は、PD制御 を用いて動翼の角度制御を行います。微分 ゲインをそれぞれ
簡単のために下記の仮定をおくと、動翼角度のフィードバックループ は、図5のように表されます。
・動翼角度は誤差なく計測できる
・モータドライバの電圧制御は正確かつ時定数が小さく、モータ電圧指令値とモータ電圧は等しいとみなせる
図5 動翼角度フィードバック系のブロック線図
伝達関数 の導出とボード線図
図5の動翼角度フィードバック系について、伝達関数 とボード線図を確認します。
開ループ伝達関数
一方、閉ループ伝達関数
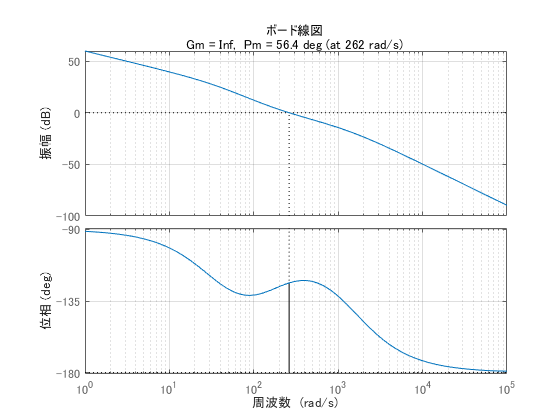
MATLAB を使えば、簡単にボード線図が書けて、位相余裕とゲイン余裕も分かっちゃいます。
上記のコードを実行すると、図6および図7が得られます。
margin関数を用いると、ボード線図と同時にゲイン余裕と位相余裕も得られちゃいます。
位相余裕は56.4度、位相が-180度以下にならないためにゲイン余裕は無限大となっています。
位相余裕、ゲイン余裕ともに充分でしょう。
図6 動翼角度フィードバック系の開ループ
伝達関数 のボード線図
ある程度の周波数まで振幅・位相ともに0付近であり、その後どちらも下がっていく理想的な形ですね。
振幅が-3 dBになる周波数は395 rad/s ≒ 63 Hzです。このくらい高い周波数まで追従可能なら、安いPWM
サーボモータ を買うのではなく、MAXONモータを使って制御した意味があると言えるのではないでしょうか。
図7 動翼角度フィードバック系の閉ループ
伝達関数 のボード線図
3.3 全体のモデル化
3.3.1 機体系のモデル化とパラメータ推定
図2において機体系は、動翼角度と対気速度を入力、ロール角を出力としています。この部分をもう少し詳しく見てみましょう。なお、簡単のためにロール以外の他2軸の運動がロール運動へ与える影響は無視しています。
機体のロール軸まわりの主慣性モーメントを
これを伝達関数 表現になおすと、式(5)となります。
もともとCREATEでは、ロケットの重量と重心を管理して設計するために、部品1つ1つの重量と位置を丁寧に登録しながら3D CAD上で機構設計をしていました。おかげで、慣性モーメントもすぐに求まり助かりました。
また、動翼角度
機軸方向以外の対気速度は無視でき、動翼角度=迎え角であるという仮定を置いています。また他の重要な仮定として、迎え角が小さく失速しないことがあります。失速すると
係数 CFD解析の詳細は、他メンバーが担当したため割愛します。
対気速度は20, 40, 60, 80 m/sの4段階、動翼角度は1, 3, 5, 7, 9, 11, 13, 15 degの8段階、計32通りの解析に最小二乗法を適用し、係数Matlab コードは下記です。
図8に動翼角度とロールモーメントの関係を示します。動翼角度が大きいときもCFD解析結果が近似結果の直線に乗っており、失速していないことが確認できます。
また、図9に対気速度とロールモーメントの関係を示します。こちらは、CFD解析結果が近似結果の二次曲線に乗っています。
図8 対気速度ごとの動翼角度とロールモーメントの関係。青丸でCFD解析結果、赤線で最小二乗法で求めた近似結果をそれぞれ示す。
図9 動翼角度ごとの対気速度とロールモーメントの関係。青丸でCFD解析結果、赤線で最小二乗法で求めた近似結果をそれぞれ示す。
3.3.2 目標動翼角度決定器のモデル化
目標動翼角度決定器は、ロール角推定値と目標ロール角及び対気速度推定値を入力とし、目標動翼角度を出力します。3.1節で示したように、後段の動翼角度制御器が、この目標値へ向けて動翼を制御します。
今回は、PD制御を用いて目標ロールモーメント
対気速度がある値
3.3.3 伝達関数 の導出とボード線図
簡単のために下記の仮定をおくと、図2のブロック線図は図11のように簡易化できます。
・ロール角は誤差なく計測できる
・対気速度は誤差なく計測できる
・対気速度はある値
図11 簡易化した全体ブロック線図
このときの開ループ伝達関数
式(3)、(7)より、開ループ伝達関数 は次のように求まります。
次に、閉ループ伝達関数
式(3)、(9)より、閉ループ伝達関数 は次のように求まります。
3.2.3節と同様にMATLAB を用いてボード線図を書きます。下記のコードを実行すると、図12および図13が得られます。
図12の開ループのボード線図を見ると、位相余裕は52.8度、ゲイン余裕は34.3 dBです。今回は目標ロール角一定の定値制御であることもあり、余裕はより小さくとも問題ないとも考えられます。しかし、4.3節に後述するように対気速度推定値の精度に不安があること、ここまでのモデル化で複数の仮定を用いた簡易化を行っておりそれが妥当であるか不安があること、本番一発勝負なのでぎりぎりを攻めたくないことから余裕は大きくとることとしました。
図13の閉ループのボード線図を見ると、振幅が-3 dBになる周波数は22.4 rad/s ≒ 3.6 Hzです。ロール制御が可能な時間は7秒間程度あるので、十分な制御帯域と言えます。
図12 系全体の開ループ伝達関数 のボード線図
図13 系全体の閉ループ伝達関数 のボード線図
4. シミュレーションと事前調整
4.1 動翼角度制御のシミュレーション
ここまでボード線図上で安定性を確認してきましたが、次は時系列シミュレーション上で確認します。まず、動翼角度制御のシミュレーションを行います。
式(1)及びラプラス 逆変換を用いると、時間領域では式(12)のように書けます。
PD制御を用いてモータ電圧オイラー 法の積分 を用いて
シミュレーション周期は10000 Hz、制御周期は500 Hzとしています。また電源電圧を10 Vに設定し、±10 V以上のモータ電圧とならないよう制限をほどこしています。
図14にシミュレーション結果を示します。すばやく目標値へ収束していることが分かります。また、伝達関数 では表現されていない電圧の上下限があっても、問題なく制御できていることが確認できます。
図14 動翼角度制御シミュレーション結果。上段にモータ電圧、下段に目標動翼角度及び動翼角度を示す。
本記事では詳細を割愛しますが、飛行中に動翼が受ける空力がうむ、動翼を回転させるモーメントによって発生する動翼角度偏差が十分に小さいことも、シミュレーションにより確認しました。
4.2 ロール制御のシミュレーション
次に、4.1節の動翼角度制御シミュレーションを組み込んだ、ロール制御全体のシミュレーションを行います。
図10のブロック線図のように目標動翼角度を定め、その目標値へ向けて4.1節と同様に動翼角度を制御し、得られた動翼角度と式(4)を用いてロール角加速度オイラー 法の積分 により
シミュレーション周期と制御周期は4.1節と同様としています。また、目標動翼角度を±14度に制限しています。
図15にシミュレーション結果を示します。約0.5秒で目標ロール角付近に収束しており、問題なく制御できていることが確認できます。
図15 ロール制御シミュレーション結果。上段に目標ロール角及びロール角、中段に目標動翼角度及び動翼角度、下段にモータ電圧を示す。
4.3 初期値及び誤差の考慮
4.2節で実施したシミュレーションは、制御開始時のロール角速度がゼロであったり、制御に用いる状態量は真値を使用していたりと、理想的な条件となっています。
本記事ではその結果は示しませんが、4.2節のコードを改良して下記の要素入れたシミュレーションを実施し、その場合でも目標ロール角へ収束することを確認しています。
① 大きな初期ロール角速度を持つ
② 固定翼のミスアラインメント等に起因する外乱ロールモーメントが存在する
③ ギアのバックラッシに起因する動翼角度計測誤差が存在する
④ ロール角速度の計測に遅れが存在する
⑤ 大きな対気速度計測誤差が存在する
5章で後述するように、実機では飛翔の途中でロール制御を開始しています。外乱ロールモーメントの状況しだいでは、制御開始時に大きなロール角速度を持っているため、その場合でも問題ないことを①で確認しました。
②では、CREATEの過去機体データを参考に、式(4)の左辺に外乱ロールモーメントを正弦波の形で付加し確認しました。
③では、ギアのカタログに記載があるバックラッシ値を用い、式(6)における動翼角度と動翼角度制御器が用いる動翼角度に差を設けて確認しました。
MEMSセンサMPU9250の角速度出力にローパスフィルタを設定していました。さらに、そのセンサ値からロール角速度を計算した後に、ローパスフィルタを施しました。これらによる遅れを考慮し④では、真のロール角速度及びロール角と、目標動翼角度決定器が用いる値に差を設けて確認しました。
⑤が最も大きな問題でした。ピトー管の信頼性が低くかったため、対気速度推定値と真値が最大1.5倍ずれていても安定となることを確認しました。具体的には、式(7)において分母と分子に登場し打ち消しあっている
5. ロール制御実験
5.1 実験条件
5.1.1 飛行プロファイル
ここまで、事前のロール制御系設計について紹介しました。5章では、実際に打ち上げた際の結果を紹介します。
図16に飛行プロファイルを示します。横軸は離床を基準とした時刻、縦軸は気圧センサのデータから算出した高度です。
C-59Jは、エンジン燃焼開始の直後に離床し、離床後約2.7秒で燃焼終了しました。
その後は約7秒間の弾道飛行の後、最高高度の約1秒後にパラシュートを開放し、減速落下しました。
安全性に配慮した自主的な規制により、ロール制御はエンジン燃焼終了後に開始することとしました。また、パラシュート開放後は大きな対気速度が得られず、動翼がロールモーメントを発揮できないため、ロール制御が成り立ちません。
よって、ロール制御は弾道飛行中にのみ、約7秒間実施しました。
図16 飛行プロファイル
5.1.2 パラメータ設定
動翼角度制御における制御ゲインは、
目標動翼角度決定器における制御ゲインは
また、ESP32への実装にあたっては、ノイズの影響を低減するため、制御に用いる計測値の一部にデジタルローパスフィルタを施しました。
ピトー管から算出した対気速度には、カットオフ周波数20 Hzの1次のデジタルローパスフィルタを施しました。
MEMS角速度センサから算出したロール角速度には、カットオフ周波数50 Hzの1次のデジタルローパスフィルタを施しました。
5.1.3 初期値
ロール制御開始時において、ロール角は125.5 deg、ロール角速度は-69.45 deg/sでした。
5.2 実験結果
5.2.1 動画による確認
実験結果を、まずは動画で定性的に確認しましょう。
右側が機体に搭載した小型カメラを用いて撮影した映像です。映っている黒い板が動翼です。
中央上が、MEMSジャイロセンサを用いて計測した機体姿勢を、CGで再現した映像です。中央下が、ロール角のグラフです。
左側上が、エンコーダで計測した動翼角度を、CGで再現した映像です。左側下が動翼角度のグラフです。
VIDEO
離床すると、C-59Jはロールしています。これは、機体後端にある固定翼のミスアラインメント、ノーズ形状の非対称性等により発生した、外乱ロールモーメントの影響と考えられます。
離床の約2.7秒後にロール制御が開始され、動翼が動き始めます。その後すぐに、ロールがほぼ停止していることが分かりますね!
5.2.2 計測データによる確認
図17に、ロール角の時間変化を示します。
青色で示したロール制御開始前は、ロール角が変化していることが分かります。
一方、ロール制御開始後は、素早く目標ロール角に収束しています。
図17 ロール角の時間変化。ロール制御開始前を青色、開始後を赤色で示す。
図18に、ロール制御開始直後の、ロール角の時間変化を示します。
整定時のロール角を90度とみなすと、整定時間 (95%) はたったの0.27秒 でした!
図18 ロール制御開始直後におけるロール角の時間変化
図19に、ロール制御開始からパラシュート開放付近までの、ロール角の時間変化を示します。
制御開始直後を除き、目標ロール角からの偏差が±4度以内 に抑えられていることが分かります。
図19 ロール制御開始からパラシュート開放付近までのロール角の時間変化
図20に、動翼角度および目標動翼角度の時間変化を示します。
モータ軸に取り付けたエンコーダで計測しているので、ギアボックスおよび傘歯車のバックラッシが計測できない誤差として存在はしていますが。
図20 動翼角度および目標動翼角度の時間変化。動翼角度は、ロール制御開始前を青
6. おわりに
皆さんもぜひ、挑戦してみてください。打ち上げ本番は胃がキリキリして楽しいです!